
 Getting started
Getting started Learn about vulnerability types
Learn about vulnerability types  Getting started in bug bounties
Getting started in bug bounties  Test your knowledge
Test your knowledge Free Web Application Challenges
Free Web Application Challenges Guides for your hunts
Guides for your hunts  ZSeano's Methodology
ZSeano's Methodology Effective Note Taking for bug bounties
Effective Note Taking for bug bounties Useful Resources
Useful Resources  Disclosed HackerOne Reports
Disclosed HackerOne Reports  Our community
Our community Endorsed Members
Endorsed Members Hackevents
Hackevents  Member Articles
Member Articles Making use of Javascript (.JS) files
Javascript (.js) files store client side code and can act as the back bone of websites, especially in modern times. As technology grows I have discovered that more and more websites will list lots of interesting information in .js files, for example when browsing the source of a website you will may see references to main.js and app.js which is ReactJS. These websites rely heavily on javascript and making ajax requests. These files will contain pretty much everything about this app, but ALSO they will make use of specific unique Javascript files for each endpoint. (seen below).
Javascript files help websites perform certain functions such as monitoring when a certain button is clicked, or perhaps when a user moves their mouse over an image or even make requests on behalf of the user (to retrieve information for example). Sometimes developers can obfuscate their javascript code which makes it unreadable to the human eye, however most types of obfuscation can be reversed as we explain below.
.js files are often easily overlooked because they contain lots of "weird" looking code which doesn't make too much sense however you just need to know what keywords to search for to extract the useful information. Over time the more you read javascript you will begin to piece it together & understand how it works. This is where understanding code and learning javascript will help you in your bug bounty journey.
Finding .js files
Fairly self explanatory. We need to first find .js files to read. You could very simply just right click on the page you're on and click "view source" (or visit view-source:https://www.website.com/), then begin looking for ".js" in the HTML. If you're a manual hacker then this is the prefered approach as you will notice that certain .js files only contain code for the specific endpoint you're on. For example imagine you are on "https://www.bugbountyhunter.com/challenge" - you may find "challenge.js" which is specificially only for this endpoint. It may contain new api endpoints you didn't know existed.
When spidering via Burp suite you will also discover lots of JS files which you should begin investigating, and as mentioned above if the target website uses ReactJS then you will find main.js and app.js.
What you're looking for
- New endpoints
- New parameters
- Hidden features. Not available on the web applicaiton but the code exists for the feature. Premium only? Can you interact with it as non premium?
- Api keys
- Developer comments (for example // this is a dev comment or /* this is a multi line dev comment */) can sometimes contain information such as when the code was published or any updates that have occured (in the past I have found notes regarding XSS filtering which helped me to understand how they fixed it and thus lead to a bypass). If the code is old there is more chance of you finding an issue!
An example of reading .js files on ReactJS
Imagine you are on https://www.example.com and you upon viewing the source you discover an "app.js" file. As well this, when visiting https://www.example.com/settings, you would see a settings.js file.

However at this point app.js is our focus. What are we looking for? New endpoints, parameters and perhaps api keys. Upon opening it we are greeted with what appears to be "gibberish"

First Step: BEAUTIFY. Beautifying will turn our code into read-able code which you can follow and understand. Copy the contents of the code and use a Javascript beautifier such as https://beautifier.io/

Now our code is readable, let's begin looking for new endpoints, parameters and perhaps api keys. In the example below (which is a real website), from searching for the keyword
pathnameI was able to find all endpoints used on the website which expanded the attack surface to look for bugs, as well as begin finding information on their API.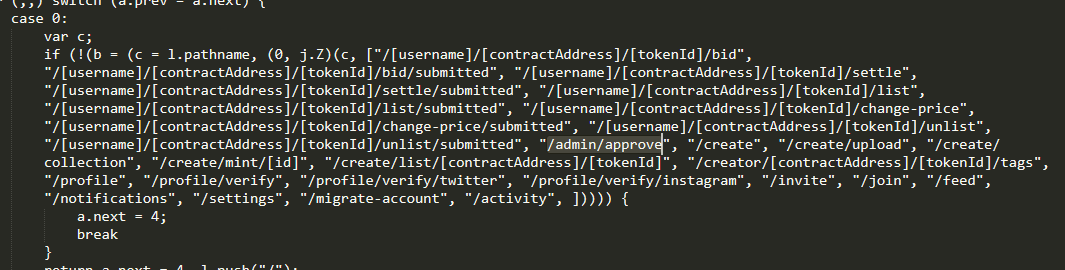

Other common keywords to look for:
url:,POST,api,GET,setRequestHeader,send((yes with just one (, as it's used when making Ajax requests!..headers,onreadystatechange,var {xyz} =,getParameter(),parameter,.theirdomain.com,apiKey.Those keywords will help us expand our attack surface, but what about postMessage bugs, DOM XSS and maybe redirects? Here are some example keywords to look out for:
postMessage,messageListener,.innerHTML,document.write(,document.cookie,location.href,redirectUrl,window.hash. The more you are reading some javascript files the more you may discover about your target and certain patterns for API endpoints (such as versions or names of endpoints).
As you can see we have managed to start increasing our data on this target website from reading their .js files and looking for specific keywords. From this we were able to discover new endpoints (which lead onto more .js files!) and more knowledge around our target. One thing to note is to not waste time browsing things such as jquery.js. Typically these files do not contain anything that will be of use to you. Go for the custom made .js files referenced.
The main aim when looking for .js files and reading them is to expand your attack surface by discovering endpoints, parameters, keys, sinks (dom xss) and overall more knowledge on your target. For example if you know they rely heavily on javascript files then you can setup a script to automatically detect any changes and get notified on new endpoints instantly!
Reading JS files on non ReactJS websites are no different. Find .JS files referenced and used and use the same approach to look for certain keywords!
Automating reading .js files
Another approach is to use a tool called GetJS by 003random which can be found here: https://github.com/003random/getJS. GetJS will take a list of domains and extract any .js files found on each domain. This is useful if you want to sort through lots of .js files for new urls/endpoints (which we explain below) on a mass scale. If the website you are testing does contain a specific .js file for each feature/endpoint, then you could begin scanning for endpoints to discover new JS files.
As well as this, Jobert Abma released a tool called Relative URL Extractor which can be found here - https://github.com/jobertabma/relative-url-extractor. An alternative is GoLinkFinder by 0xsha which can be found here - https://github.com/0xsha/GoLinkFinder. Both will help aid with extracting useful information from JS files if you're not comfortable reading javascript.
Deobfuscating javascript
Sometimes javascript will be obfuscated so it's not readable even after beautifying. Sometimes it can be tricky to deobfuscate but de4js is a great online tool which can deobfuscate most types of Javascript & make it readable: https://lelinhtinh.github.io/de4js/
Reading JS to a real finding
This is information on a real finding (website redacted). On this particular website when visiting https://www.example.com/login I noticed in the javascript the following:
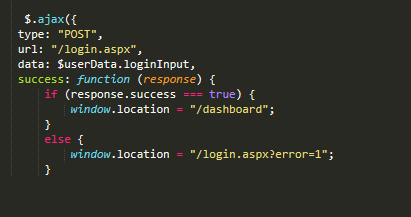
This code would send a POST request to /login.aspx and upon success it would redirect to /dashboard. Visiting example.com/dashboard would automatically redirect me to example.com/login, BUT it was via a META REFRESH and the response contained HTML and references to more .JS files. First mistake!
Browsing the contents I noticed again the use of more JavaScript code referencing even more endpoints, except this time they were on AppSpot.com. Since it was now making calls to an external domain, I just knew there would be no session handling.. oh and the fact that the API-KEY needed to make calls was referenced also. Let’s test this!
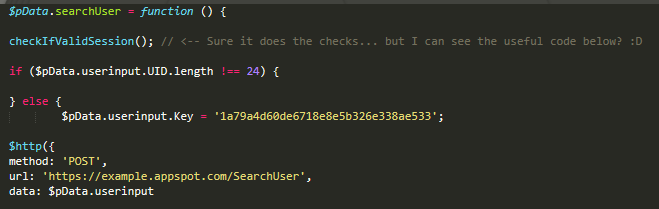
After sending a request to the appspot URL with the required API-KEY it responded with what looked like an encrypted string. Interesting, what does this do? We’re getting closer, but nothing interesting to report so far. Anytime I see interesting encryption being used, IDs, parameter names etc,I note it down, and we have a great guide on it here.
From reading my notes I remembered I had found this type of value being used elsewhere and in this case there was another endpoint on a completely different subdomain which took this encrypted ID as an parameter value which would respond PII information about the user. Success and 4 digit bounty!.
Just because a page redirects, find out how & why. Is it because you are not authenticated?Does it load via 302 header, or is it redirecting via some javascript/meta refresh? If so, is there anything of interest in the code the page is redirecting away from?